Back again!
Today We will try to go a bit deeper into Dynamic Linker
Here is the shortened version of presentation that I created around 2 years ago: Dynamic Linker
Its a short guide to symbol relocations, including relative and named relocations, how elf works, what for we have a symbol hash table, what is all about with table size vs chain length in gcc ? Moreover GOT (Global Offset Table) and PLT (Procedure Linkage Table) with some dlopen parameters explanation (very basic). Finishing with Position Independent Code and how harmful text relocations may be for overall performance.
I hope that after this short presentation you will be aware that memory pages may be swapped from read only to write memory - thus creating potential attack vector for crackers. Moreover you will understand that it's is internally not as simple at it may look like at the beginning thus we have to remember that GOT and PLT indeed exist under the hood. This will be very important in our 3rd Part of performance for dynamic libraries post. You may even now remember from my post about tcmalloc that we were able to use tcmalloc only because malloc is a weak symbol thus can be overloaded with a little help from LD_PRELOAD. You can even remember our bug that we faced that has been described (here: tcmalloc post) was strongly connected to PLT.
Everything I post here is mostly for myself, it works as a reminder, it sums up some work, it allows me to keep track of my old work that has been already done. There is plenty of stuff that I was working on and this blog goal is to make it unforgotten.
11.4.16
Shared Libraries from performance point of view... Introduction [Part 1]
Hi, its been a while since my last post here, but there was a good reason for not posting anything and this particularly means that i was spending time learning new things and meanwhile i was also able to check some of my shared libraries that I'm working with in terms of performance.
So let me present some of my thoughts, but firstly let me start with SO introduction, from high level to low level stuff.. . For all UNIX developers most of this stuff should be already known, but i hope even some of you will find it useful.
Let's start!
Static linking vs Dynamic linking


I could not make it more clear than those two simple pictures. So I hope we are all fine with quick introduction what dynamic linking is.. ;) Now let's go just a bit deeper (still floating! ;) ).
Dependent vs Runtime loaded library
Now here for new folks things are getting a bit more interesting. We can distinguish two types of dynamic libraries - dependent one and runtime loaded one. Let me show you a simple code to distinguish those two:
OK now you may be a bit confused. Let's try to clarify it, briefly as we are going to jump to much more interesting features. Runtime loaded means that Library is loaded on request dynamically, whereas dependent one are specified at link time for your product (but same reference symbol policy applies as on slide static vs dynamic linking). Runtime loaded libraries are more natural when we talk about dynamic objects. But you have to be aware that dynamic lib. does nto always mean this same. So keep it in mind it will be needed later.
What for we are using dynamic libraries at all ?
Well apart from many different reasons that some people may like to tell you why dynamic is good, I just want to focus on the most important one from my perspective - hot loads - which means no more than that you do not have to recompile a whole project but its enought to provide a new lib that will be hot swaped with old one. Interesting, but also dangerous! In fact very dangerous.. but yet still used in some production envoronments (be aware we are talking here about pure dynamic ( i like to name them like that) runtime loaded libraries (dlopen!).
But as you may think (and you are right!) there is no hot swap without.. compatibility! and that compatibility is for many reasons crucial for any library developer - especially backward compatibility! So let's take a look what compatibility means for us.
In fact we are still in very basic parts of dynamic libraries, but that is good, we have to understand them correctly to go deeper into performance point of view. So if any concept that was mentioned before is not clear, please clarify it before going deeper. Ok? Ok let's take a look on something that from developer point of view is one of the most important part of any library, Library Interface.
Library Interface
This should be clear, as library we are obliged to export interface for our clients (that in most cases is unknown for us). There are some basic rules for defining an Library Interface. FIrstly, functions on client side are referenced (linked) to implementation and that dependency may be resolved during link time or latter (lazily). Secondly we should export (i use this term intentionally) functions that are going to be interface and we should export only header files. Moreover we shoudl export wrappers only. Good example for such wrapper function may be a sort example.
What that means ? It means that internall specifix functions should be usually hidden, and wrappers should be able to choose which one is the best one to use for specified data (for example). Internally inside Library we should call internall functions directly (it will reduce overall performance). And to make it all clear and enjoyable we should define some export strategy for our library. Briefly what when and how we are going to export our interface - and that kind of crucial info we should provide as starting doc for any library developer that is going to contribute.
Library Dependencies
When you write your own library you are usually using also some other libraries that you depend on.
Very easy way to check on what kind of libraries you have a dependency is to use:
readelf -d yourlibrary.so
that will produce for you output that partially looks like:

What is interesting from dependency point of view here is (NEEDED) that is nothing more than DT_NEEDED that we will discuss a bit latter on. NEEDED are libraries that your library is dependent on and that will be used when searching for symbol signature to resolve. In my case as you can see we have quite a lot depndencies for this particular library including libraries like libc libgcc and libstdc++ or even libpthread (that is 100% normal). Important note to remember:
More dependent libraries your library has, the longer it takes for your library to load! You should keep to minimum (only the ones that you really need) number of external references to symbols in dependent libraries. This practice will further optimize your library load time. There is one more thing when we discuss library dependencies, when we are loading dependencies dynamically some libraries may need to initialize firstly some values/allocators/whatever and each library developer has to take care about that part by specializng (if needed) library initializers and library finalizers (please pay attention that you should not name them _init nor _fini - those are system initializers that you may overwrite! and remember that you should never export them as part of your Library Interface.
How to specifce them ? Quite easy (internally inside functions its just printf example):
All is clear for now ?
I Hope yes cause it was just a quick brief to the most basic concepts of shared libraries development. In Part 2 we are going to go deeper to interesting stuff - Dynamic Liner Startup Process! So fasten your belts before Part 2.
PS. I used some photos from google to present concepts that i'm talking about.
Credits goes to : http://www.vincehuston.org/dp/all_uml.html
https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/100-Articles/DynamicLibraryDesignGuidelines.html and some that are not named because i have lost their websites ;) (ping me if you know the original source)
So let me present some of my thoughts, but firstly let me start with SO introduction, from high level to low level stuff.. . For all UNIX developers most of this stuff should be already known, but i hope even some of you will find it useful.
Let's start!
Static linking vs Dynamic linking


I could not make it more clear than those two simple pictures. So I hope we are all fine with quick introduction what dynamic linking is.. ;) Now let's go just a bit deeper (still floating! ;) ).
Dependent vs Runtime loaded library
Now here for new folks things are getting a bit more interesting. We can distinguish two types of dynamic libraries - dependent one and runtime loaded one. Let me show you a simple code to distinguish those two:
 |
| Dependent library |
 |
| Runtime loaded library |
 |
| Runtime loaded way of use |
 |
| How runtime loaded libraries really works.. |
OK now you may be a bit confused. Let's try to clarify it, briefly as we are going to jump to much more interesting features. Runtime loaded means that Library is loaded on request dynamically, whereas dependent one are specified at link time for your product (but same reference symbol policy applies as on slide static vs dynamic linking). Runtime loaded libraries are more natural when we talk about dynamic objects. But you have to be aware that dynamic lib. does nto always mean this same. So keep it in mind it will be needed later.
What for we are using dynamic libraries at all ?
Well apart from many different reasons that some people may like to tell you why dynamic is good, I just want to focus on the most important one from my perspective - hot loads - which means no more than that you do not have to recompile a whole project but its enought to provide a new lib that will be hot swaped with old one. Interesting, but also dangerous! In fact very dangerous.. but yet still used in some production envoronments (be aware we are talking here about pure dynamic ( i like to name them like that) runtime loaded libraries (dlopen!).
But as you may think (and you are right!) there is no hot swap without.. compatibility! and that compatibility is for many reasons crucial for any library developer - especially backward compatibility! So let's take a look what compatibility means for us.
 |
| Compatibility between client and Draw Library |
I think its clear enought, but let's make it a bit harder.. Can Client 1.1 use Draw 1.0 Library ? Normally no.. but if Client 1.1 has draw_polygon() declared as WEAK_IMPORT than it can! weak_import attribute tells us that this dependency is optional, but there is more, cause dynamic loader performs version compatibility test only with dependent libraries. Dynamic libraries opened at runtime with dlopen don't go throught this test! Ops.Moreover you can check functions against NULL to check if they are supported in the particular dynamic library that the code is currently running against. It seems like a lot of different possibilities!
 |
| weak_import attribute example |
Library Interface
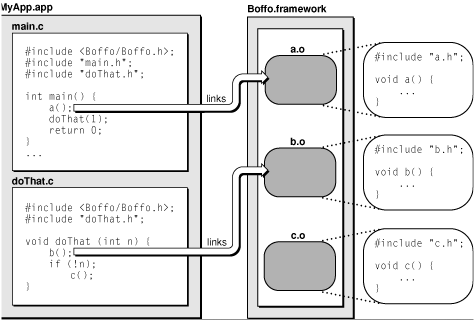 |
| Library Interface |
 |
| Interface dependent vs runtime loaded |
This should be clear, as library we are obliged to export interface for our clients (that in most cases is unknown for us). There are some basic rules for defining an Library Interface. FIrstly, functions on client side are referenced (linked) to implementation and that dependency may be resolved during link time or latter (lazily). Secondly we should export (i use this term intentionally) functions that are going to be interface and we should export only header files. Moreover we shoudl export wrappers only. Good example for such wrapper function may be a sort example.
 |
| Wrapper Example |
Library Dependencies
When you write your own library you are usually using also some other libraries that you depend on.
Very easy way to check on what kind of libraries you have a dependency is to use:
readelf -d yourlibrary.so
that will produce for you output that partially looks like:

What is interesting from dependency point of view here is (NEEDED) that is nothing more than DT_NEEDED that we will discuss a bit latter on. NEEDED are libraries that your library is dependent on and that will be used when searching for symbol signature to resolve. In my case as you can see we have quite a lot depndencies for this particular library including libraries like libc libgcc and libstdc++ or even libpthread (that is 100% normal). Important note to remember:
More dependent libraries your library has, the longer it takes for your library to load! You should keep to minimum (only the ones that you really need) number of external references to symbols in dependent libraries. This practice will further optimize your library load time. There is one more thing when we discuss library dependencies, when we are loading dependencies dynamically some libraries may need to initialize firstly some values/allocators/whatever and each library developer has to take care about that part by specializng (if needed) library initializers and library finalizers (please pay attention that you should not name them _init nor _fini - those are system initializers that you may overwrite! and remember that you should never export them as part of your Library Interface.
How to specifce them ? Quite easy (internally inside functions its just printf example):
 |
| Library constructor (initializer) |
 |
| Library destructor (finalizer) |
I Hope yes cause it was just a quick brief to the most basic concepts of shared libraries development. In Part 2 we are going to go deeper to interesting stuff - Dynamic Liner Startup Process! So fasten your belts before Part 2.
PS. I used some photos from google to present concepts that i'm talking about.
Credits goes to : http://www.vincehuston.org/dp/all_uml.html
https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/100-Articles/DynamicLibraryDesignGuidelines.html and some that are not named because i have lost their websites ;) (ping me if you know the original source)
7.8.15
Numbers non-uniform probability distribution in C++
Let's consider one simple case. If you got:
array = {-10, 3, 9, 0, 111, 99}
and probability distribution
distr = {0.07, 0.2, 0.1, 0.33, 0.07, 0.23}
Can you write C/C++ code (not using C++11) that will guarantee (more or less) that
nextVal() function will return randomly next value from array with given probability ?
So it means after 100 executions of nextVal more or less you should see that nextVal numbers are aligned with probability distribution: perfectly (7,20,10,33,7,23) .
It is an easy task but if you are struggled , feel free and take a look (it's not optimized):
#include <iostream>
#include <cmath>
#include <time.h>
#include <stdlib.h>
#include <map>
#include <vector>
using namespace std;
#define ARRAY_SIZE(array) (sizeof(array)/sizeof(array[0]))
int checkDistribution(double random, const map<double, vector<int> > &distribution_map)
{
int index = 0;
map<double, vector<int> >::const_iterator it = distribution_map.begin();
for (; it!=distribution_map.end(); ++it)
{
if (random < (*it).first)
{
int randomInternal = 0;
if ((*it).second.size() > 1)
randomInternal = rand() % ((*it).second.size());
index = (*it).second.at(randomInternal);
break;
}
}
return index;
}
void nextNum(int* results, const map<double, vector<int> > &distribution_map)
{
double random = (double) rand()/RAND_MAX;
int index = checkDistribution(random,distribution_map);
results[index]+=1;
}
int main() {
srand (time(NULL));
int results [] = {0,0,0,0,0};
int numbers [] = {-1,0,1,2,3};
double prob [] = {0.01, 0.3, 0.58, 0.1, 0.01};
int size = ARRAY_SIZE(numbers);
// Building Distribution
map<double, vector<int> > distribution_map;
map<double, vector<int> >::iterator it;
for (int i = 0; i < size; i++)
{
it = distribution_map.find(prob[i]);
if (it!=distribution_map.end())
it->second.push_back(i);
else
{
vector<int> vec;
vec.push_back(i);
distribution_map[prob[i]] = vec;
}
}
// PDF to CDF transform
map<double, vector<int> > cumulative_distribution_map;
map<double, vector<int> >::iterator iter_cumulative;
double cumulative_distribution = 0.0;
for (it=distribution_map.begin();it!=distribution_map.end();++it)
{
cumulative_distribution += ((*it).second.size() * (*it).first);
cumulative_distribution_map[cumulative_distribution] = (*it).second;
}
for (int i = 0; i<100; i++)
{
nextNum(results, cumulative_distribution_map);
}
for (int j = 0; j<size; j++)
cout<<" "<<results[j]<<" ";
return 0;
}
31.7.15
Patricia/Radix tree - in-memory data manipulation
I was planning to write continuation post about SOA optimizations, but 'accidentally' I had a chance in last few weeks to code something a bit more interesting from my developer perspective. Not well known and not frequently and widely used in most companies (apart from those which are dealing with in-memory operations) : Radix trees!
Storing and retrieving strings in memory is a fundamental problem in computer science. The efficiency of string data structures used for this task is of paramount importance for applications such as in-memory databases, text-based search engines and dictionaries. The burst tree( http://www.cs.uvm.edu/~xwu/wie/CourseSlides/Schips-BurstTries.pdf ) is a leading choice for such tasks, as it can provide fast sorted access to strings. The burst trie, however, uses linked lists as substructures which can result in poor use of CPU cache and main memory. Thus, engineering a fast, compact, and scalable tree for strings remains an open problem. We will take a look here at Radix tree, which is one of possible way how to handle this fundamental problem and you can treat it as introduction to in-memory data handling.
To make a long story short, here is the radix tree structure
As we can see, we have here a kind of structural space optimization, and also quite efficient search structure. Apart from what you see on the picture, it is not binary tree. And here in fact magic happens!
Building a simple radix tree is not much different from non binary tree setup, but if we use this structure wisely we can on top of it create a powerfull searching mechanism that can align our tree to some specific group size, meaning that each tree level will try to be as close to this group size. Is it not fantastic ? Imagine that you are working on a node with limited memory, or when using simple radix tree you want to speed up you searches, for both tasks radix tree level grouping algorithm presented below could be a good choice (But there are better choices also! like HAT-Trie for example)
Comparing this structure with any other balanced tree or hashed structures we are gaining in two places. First is space, and second is number of comparision needed to find desired key. Hashmaps are special here cause you can think that they are faster, which is not necesairlly true if you consider hash algorithm then worst-case time is much higher then the one in radix tree.
#include <iostream>
#include <string.h>
#include <stdio.h>
using namespace std;
struct node
{
string key;
int len;
node* link;
node* next;
int before;
node(const string &x) : link(0), next(0)
{
len = x.size() + 1; // Used for split purposes,
key = x;
}
node(const string &x, int n) : link(0), next(0)
{
key = x.substr(0,n);
len = n;
}
~node() {}
};
class stringTree
{
public:
node* root;
int target_size;
public:
stringTree(int targetSize):root(0), target_size(targetSize){}
stringTree(const string& x, int targetSize): root(0), target_size(targetSize){root = internal_insert(root,x);}
public:
void insert(const string& x)
{
if (root)
internal_insert(root,x);
else
root = internal_insert(root,x);
}
void display()
{
if (root)
{
redesign_postorder(root,root,0,0);
internal_display(root,0);
}
}
bool find(const string &x)
{
if (root)
return internal_find(root, x, 0)==NULL?false:true;
return false;
}
private:
int countChilds(node* t)
{
int size = 1;
if (t->len == 1 && t->key==" ") // Hack for ' ', same keys are stored as len=1 empty strings
size--;
node* iterator = t;
while (iterator->next)
{
if (iterator->next->before < size)
iterator->next->before = size;
iterator = iterator->next;
size++;
}
return size;
}
void redesign_postorder(node* oldt, node* t, int levelSize, int groupSize)
{
if (t==NULL) return;
redesign_postorder(t,t->link,levelSize+1,0);
redesign_postorder(t,t->next,levelSize,groupSize+1);
if (oldt->link && groupSize==0)
{
int numberOf = countChilds(oldt);
int numberOfInternal = countChilds(t);
numberOf+=groupSize;
numberOf+=oldt->before;
if (numberOf<target_size && ((numberOf+numberOfInternal)<=target_size))
join(oldt);
}
}
void internal_display(node* t,int level)
{
if (t == NULL) return;
for (int i = 0; i < level;i++)
printf("\t");
printf("node...: %s \n", t->key.c_str());
internal_display(t->link,level+1);
internal_display(t->next,level);
}
node* internal_insert(node* t, const string &x, int n=0)
{
if( !n ) n = x.size()+1;
if( !t ) return new node(x);
int k = prefix(x,n,t->key,t->len);
if( k==0 )t->next = internal_insert(t->next,x,n);
else if( k<n )
{
if( k<t->len )
split(t,k);
t->link = internal_insert(t->link,x.substr(k),n-k);
}
return t;
}
int prefix(const string &x, int n, const string &key, int m)
{
for( int k=0; k<n; k++ )
if( k==m || x[k]!=key[k] )
return k;
return n;
}
void split(node* t, int k)
{
node* p = new node(t->key.substr(k),t->len-k);
p->link = t->link;
t->link = p;
string temp = t->key.substr(0,k);
t->key = temp;
t->len = k;
}
void join(node* t) // Goign to use it during tree merge to met group size conditions
{
node* p = t->link;
string temp = t->key.substr(0,t->len);
string temp2 = p->key.substr(0,p->len);
t->key = temp + temp2;
t->len += p->len;
t->link = p->link;
string tempKey = temp;
int lenghtTemp = t->len;
while(t->next)
t=t->next;
t->next = p->next;
while(p->next)
{
string tempKey2 = p->next->key.substr(0,p->next->len);
string tempKey3 = tempKey + tempKey2;
p->next->key = tempKey3;
p->next->len += lenghtTemp;
p=p->next;
}
}
node* internal_find(node* t, const string &x, int n=0)
{
if( !n ) n = x.size()+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==0 ) return internal_find(t->next,x,n);
if( k==n ) return t;
if( k==t->len ) return internal_find(t->link,x.substr(k),n-k);
return 0;
}
};
int main() {
string testowy = "amazon";
string testowy2 = "amazonadsystem";
string testowy3 = "amazonwebapps";
string testowy4 = "amazon";
string testowy5 = "amazon-adsystem";
string testowy6 = "amazonwebapps";
string testowy7 = "aol";
stringTree test(testowy,3);
test.insert(testowy2);
test.insert(testowy3);
test.insert(testowy4);
test.insert(testowy5);
test.insert(testowy6);
test.insert(testowy7);
printf("found: %d\n", test.find(testowy2));
printf("found: %d\n", test.find("bsabsha"));
printf("============================\n");
printf("TREE\n");
printf("============================\n");
test.display();
return 0;
}
Please pay attention that this code is not even close to ideal, it works but it could be done much better in some places. The intention of the code was just to show you how to build such tree. Moreover if you take a closer look at redesign_postorder function you can clearly see that postorder evaluation is a bit tricky here, cause easier and more intuitive way will be to start from bottom and go level by level up. Can you see some pros and cons of this solution with postorder ? Also did you manage to see that redesign_postorder is indeed doing level grouping here ? Another interesting question could be: Can instead of tree redesign for specific level we can do it during insertion ? More interesting info and interesting structures based on radix trees could be found for example here:
http://lwn.net/Articles/175432/
http://code.dogmap.org/kart/
http://www-db.in.tum.de/~leis/papers/ART.pdf
Comments $\TeX$ mode $ON$
Storing and retrieving strings in memory is a fundamental problem in computer science. The efficiency of string data structures used for this task is of paramount importance for applications such as in-memory databases, text-based search engines and dictionaries. The burst tree( http://www.cs.uvm.edu/~xwu/wie/CourseSlides/Schips-BurstTries.pdf ) is a leading choice for such tasks, as it can provide fast sorted access to strings. The burst trie, however, uses linked lists as substructures which can result in poor use of CPU cache and main memory. Thus, engineering a fast, compact, and scalable tree for strings remains an open problem. We will take a look here at Radix tree, which is one of possible way how to handle this fundamental problem and you can treat it as introduction to in-memory data handling.
To make a long story short, here is the radix tree structure
 |
| Radix tree |
Building a simple radix tree is not much different from non binary tree setup, but if we use this structure wisely we can on top of it create a powerfull searching mechanism that can align our tree to some specific group size, meaning that each tree level will try to be as close to this group size. Is it not fantastic ? Imagine that you are working on a node with limited memory, or when using simple radix tree you want to speed up you searches, for both tasks radix tree level grouping algorithm presented below could be a good choice (But there are better choices also! like HAT-Trie for example)
Comparing this structure with any other balanced tree or hashed structures we are gaining in two places. First is space, and second is number of comparision needed to find desired key. Hashmaps are special here cause you can think that they are faster, which is not necesairlly true if you consider hash algorithm then worst-case time is much higher then the one in radix tree.
#include <iostream>
#include <string.h>
#include <stdio.h>
using namespace std;
struct node
{
string key;
int len;
node* link;
node* next;
int before;
node(const string &x) : link(0), next(0)
{
len = x.size() + 1; // Used for split purposes,
key = x;
}
node(const string &x, int n) : link(0), next(0)
{
key = x.substr(0,n);
len = n;
}
~node() {}
};
class stringTree
{
public:
node* root;
int target_size;
public:
stringTree(int targetSize):root(0), target_size(targetSize){}
stringTree(const string& x, int targetSize): root(0), target_size(targetSize){root = internal_insert(root,x);}
public:
void insert(const string& x)
{
if (root)
internal_insert(root,x);
else
root = internal_insert(root,x);
}
void display()
{
if (root)
{
redesign_postorder(root,root,0,0);
internal_display(root,0);
}
}
bool find(const string &x)
{
if (root)
return internal_find(root, x, 0)==NULL?false:true;
return false;
}
private:
int countChilds(node* t)
{
int size = 1;
if (t->len == 1 && t->key==" ") // Hack for ' ', same keys are stored as len=1 empty strings
size--;
node* iterator = t;
while (iterator->next)
{
if (iterator->next->before < size)
iterator->next->before = size;
iterator = iterator->next;
size++;
}
return size;
}
void redesign_postorder(node* oldt, node* t, int levelSize, int groupSize)
{
if (t==NULL) return;
redesign_postorder(t,t->link,levelSize+1,0);
redesign_postorder(t,t->next,levelSize,groupSize+1);
if (oldt->link && groupSize==0)
{
int numberOf = countChilds(oldt);
int numberOfInternal = countChilds(t);
numberOf+=groupSize;
numberOf+=oldt->before;
if (numberOf<target_size && ((numberOf+numberOfInternal)<=target_size))
join(oldt);
}
}
void internal_display(node* t,int level)
{
if (t == NULL) return;
for (int i = 0; i < level;i++)
printf("\t");
printf("node...: %s \n", t->key.c_str());
internal_display(t->link,level+1);
internal_display(t->next,level);
}
node* internal_insert(node* t, const string &x, int n=0)
{
if( !n ) n = x.size()+1;
if( !t ) return new node(x);
int k = prefix(x,n,t->key,t->len);
if( k==0 )t->next = internal_insert(t->next,x,n);
else if( k<n )
{
if( k<t->len )
split(t,k);
t->link = internal_insert(t->link,x.substr(k),n-k);
}
return t;
}
int prefix(const string &x, int n, const string &key, int m)
{
for( int k=0; k<n; k++ )
if( k==m || x[k]!=key[k] )
return k;
return n;
}
void split(node* t, int k)
{
node* p = new node(t->key.substr(k),t->len-k);
p->link = t->link;
t->link = p;
string temp = t->key.substr(0,k);
t->key = temp;
t->len = k;
}
void join(node* t) // Goign to use it during tree merge to met group size conditions
{
node* p = t->link;
string temp = t->key.substr(0,t->len);
string temp2 = p->key.substr(0,p->len);
t->key = temp + temp2;
t->len += p->len;
t->link = p->link;
string tempKey = temp;
int lenghtTemp = t->len;
while(t->next)
t=t->next;
t->next = p->next;
while(p->next)
{
string tempKey2 = p->next->key.substr(0,p->next->len);
string tempKey3 = tempKey + tempKey2;
p->next->key = tempKey3;
p->next->len += lenghtTemp;
p=p->next;
}
}
node* internal_find(node* t, const string &x, int n=0)
{
if( !n ) n = x.size()+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==0 ) return internal_find(t->next,x,n);
if( k==n ) return t;
if( k==t->len ) return internal_find(t->link,x.substr(k),n-k);
return 0;
}
};
int main() {
string testowy = "amazon";
string testowy2 = "amazonadsystem";
string testowy3 = "amazonwebapps";
string testowy4 = "amazon";
string testowy5 = "amazon-adsystem";
string testowy6 = "amazonwebapps";
string testowy7 = "aol";
stringTree test(testowy,3);
test.insert(testowy2);
test.insert(testowy3);
test.insert(testowy4);
test.insert(testowy5);
test.insert(testowy6);
test.insert(testowy7);
printf("found: %d\n", test.find(testowy2));
printf("found: %d\n", test.find("bsabsha"));
printf("============================\n");
printf("TREE\n");
printf("============================\n");
test.display();
return 0;
}
Please pay attention that this code is not even close to ideal, it works but it could be done much better in some places. The intention of the code was just to show you how to build such tree. Moreover if you take a closer look at redesign_postorder function you can clearly see that postorder evaluation is a bit tricky here, cause easier and more intuitive way will be to start from bottom and go level by level up. Can you see some pros and cons of this solution with postorder ? Also did you manage to see that redesign_postorder is indeed doing level grouping here ? Another interesting question could be: Can instead of tree redesign for specific level we can do it during insertion ? More interesting info and interesting structures based on radix trees could be found for example here:
http://lwn.net/Articles/175432/
http://code.dogmap.org/kart/
http://www-db.in.tum.de/~leis/papers/ART.pdf
Comments $\TeX$ mode $ON$
30.6.15
Performance optimizations in SOA - part 1
It's been a while since my last post here, but during my absence I was mainly working on performance optimizations in SOA (Service Oriented Architecture) and I would like to share with you some of my conclusions after those few months.
Whenever you have to deal with Foundation Library ( a kind of library that is widely used by many back-ends) and you want to be sure that pull requests that you are integrating are not decreasing an overall performance of the library , than apart from strict Code Reviews -> MEASURE, measure and one more time measure your library performance. I spent a week or two to build our performance dashboard (Python+JS+CSS/HTML5+C++ for library code) for library that is one of our core libraries, and a key library for data encoding/decoding. Final result looks (more or less) like:
What to measure ? And how to measure it ?
Well here things starts to be a bit more complicated, depends on the language that you are using, you can or you can not measure memory usage (let's exclude the case when you have your own memory map allocator that pre-allocates memory per object, and you are manually freeing memory from this memory allocator) . So firstly try to measure most common use cases that your library provides. Usually API from Library Manager. Secondly: Do you have a cache system in your library ? If yes than measure first read and second read (from cache). As integrator you have to have a tool that allows you to say that library is heading into wrong/good direction -> Try to build a trend graphs taking into account all previous tests, that after few months you can take a look and say to your manager that the work that you put in place for performance optimizations is going into right/wrong direction ;).
If you successfully build your Performance dashboard than you have to ensure that tests which you are running are always run in same conditions. Always use same machine with same configuration, for performance measurements, don't do it in core time when other people probably using same machine that you are using for test. Best option here is to have a separated test environment, otherwise use cron and schedule a tests somewhere in nightly hours. To reduce random factors, remove outliers from graph. Never run once if you are building trend graphs, run tests multiple times to build an average that should much better visualize a real library trends.
Let's say that you succeed and you are able now to monitor you library performance, now its time for graph analysis, which believe me is the most interesting part of work when dealing with huge foundation libraries, as if gives you an idea what is really going on in your library, and how you library behave. Take a look and try to guess what is going on:
Any guess ? Well i will answer to this "issue" in the last image,
There could be many reasons for such behavior, but it usually means that some elements are dependent on another elements (when you deal with Lazy Layers its very important to remove such dependencies as much as possible, -> dependency injection could be a good choice here).
Frankly speaking I think we all see what is going on here, bad algorithm in BOM model. But maybe we cannot do it better ? If you can.. refactor immediately!
Fragmentation that is observed here is really due to internal STL memory allocation (quite often in this case its connected to boost::multi_index structures, here you can observe how those structures behave) First and second read(from cache) is in this case OK, as cache has been already refilled, this is why its also an important factor to take a look at the numbers on the scale, otherwise we may spend some time searching for an issue where there is no issue at all. Look at the numbers at the scale -> Always.
If you get a graphs like the last one, than you are definitely not the happiest man on the earth. Cause analysis of such graphs is usually highly complicated. We can say that something is happening with library when we reach a specified number of Elements ~2000, but to find out what is really going on and from where those outliers comes from, you have to spent a bit more time with tools like valgrind, and dig deep inside the code. But hey! at least you know where to look for, without measurements you won't be able reveal most of those performance issues.
Always Measure!
Whenever you have to deal with Foundation Library ( a kind of library that is widely used by many back-ends) and you want to be sure that pull requests that you are integrating are not decreasing an overall performance of the library , than apart from strict Code Reviews -> MEASURE, measure and one more time measure your library performance. I spent a week or two to build our performance dashboard (Python+JS+CSS/HTML5+C++ for library code) for library that is one of our core libraries, and a key library for data encoding/decoding. Final result looks (more or less) like:
 |
| Example of Performance Dashboard for Foundation Library |
Well here things starts to be a bit more complicated, depends on the language that you are using, you can or you can not measure memory usage (let's exclude the case when you have your own memory map allocator that pre-allocates memory per object, and you are manually freeing memory from this memory allocator) . So firstly try to measure most common use cases that your library provides. Usually API from Library Manager. Secondly: Do you have a cache system in your library ? If yes than measure first read and second read (from cache). As integrator you have to have a tool that allows you to say that library is heading into wrong/good direction -> Try to build a trend graphs taking into account all previous tests, that after few months you can take a look and say to your manager that the work that you put in place for performance optimizations is going into right/wrong direction ;).
 | |
| Trend graph for library |
If you successfully build your Performance dashboard than you have to ensure that tests which you are running are always run in same conditions. Always use same machine with same configuration, for performance measurements, don't do it in core time when other people probably using same machine that you are using for test. Best option here is to have a separated test environment, otherwise use cron and schedule a tests somewhere in nightly hours. To reduce random factors, remove outliers from graph. Never run once if you are building trend graphs, run tests multiple times to build an average that should much better visualize a real library trends.
Let's say that you succeed and you are able now to monitor you library performance, now its time for graph analysis, which believe me is the most interesting part of work when dealing with huge foundation libraries, as if gives you an idea what is really going on in your library, and how you library behave. Take a look and try to guess what is going on:
 |
| Did you see this "fragmentation" jumps ? :) |
Any guess ? Well i will answer to this "issue" in the last image,
 | |
| Two different paths ? What is going on ? :) |
There could be many reasons for such behavior, but it usually means that some elements are dependent on another elements (when you deal with Lazy Layers its very important to remove such dependencies as much as possible, -> dependency injection could be a good choice here).
 |
| Well this one is easy O(n^2) |
Frankly speaking I think we all see what is going on here, bad algorithm in BOM model. But maybe we cannot do it better ? If you can.. refactor immediately!
 | ||
| Fragmentation and Cache system looks broken ? |
Fragmentation that is observed here is really due to internal STL memory allocation (quite often in this case its connected to boost::multi_index structures, here you can observe how those structures behave) First and second read(from cache) is in this case OK, as cache has been already refilled, this is why its also an important factor to take a look at the numbers on the scale, otherwise we may spend some time searching for an issue where there is no issue at all. Look at the numbers at the scale -> Always.
 | |||
| A so called mess :)))) |
If you get a graphs like the last one, than you are definitely not the happiest man on the earth. Cause analysis of such graphs is usually highly complicated. We can say that something is happening with library when we reach a specified number of Elements ~2000, but to find out what is really going on and from where those outliers comes from, you have to spent a bit more time with tools like valgrind, and dig deep inside the code. But hey! at least you know where to look for, without measurements you won't be able reveal most of those performance issues.
Always Measure!
Subscribe to:
Posts (Atom)